
Sparrow: Rollout disperso para RL estable y eficiente en contextos largos
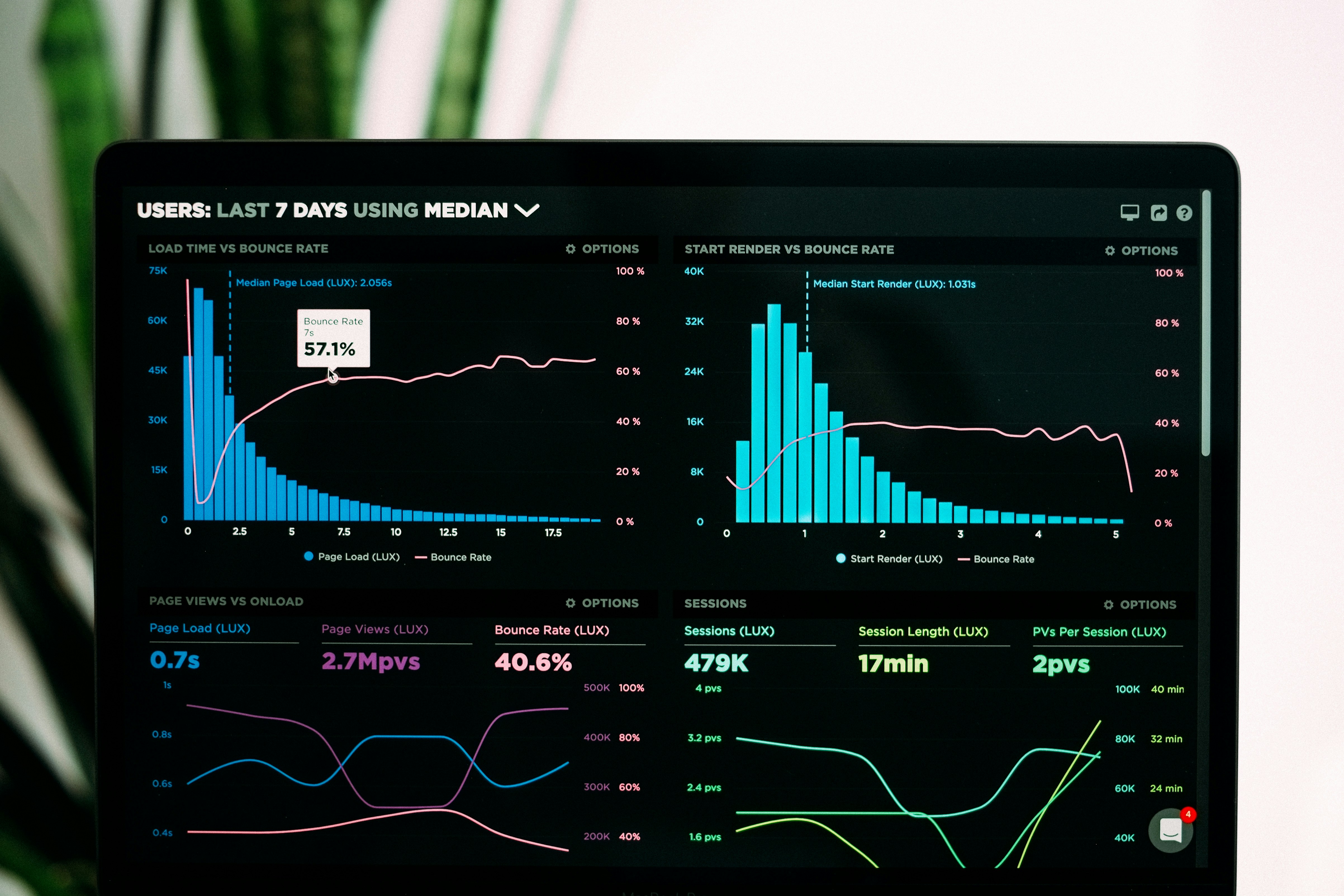
Descubre cómo Sparrow acelera hasta 2.4x el rollout en RL de modelos de lenguaje usando atención dispersa dinámica sin perder estabilidad.
Descubre cómo Sparrow acelera hasta 2.4x el rollout en RL de modelos de lenguaje usando atención dispersa dinámica sin perder estabilidad.

AdaGRPO optimiza modelos generativos con balance adaptativo de pérdida y recompensa, mejorando CTR y retención en e-commerce.

RLDT: algoritmo RL con transporte de densidad y gradiente variacional para mejorar políticas de flujo, superando a métodos previos en control continuo.

FiberTune mejora el ajuste fino de políticas VLA preservando residuos visuales clave, logrando +10.7% en éxito de tareas robóticas sin costo de inferencia.

AliyunConsoleAgent entrena agentes web para verificar documentación en consolas cloud. Combina destilación y RL, logrando 63.52% éxito con 92% menos costo.

Descubre un nuevo método para auditar estrategias de inversión en IA basado en la descomposición exacta del arrepentimiento. Ideal para evaluar carteras y mecanismos de plataforma.
Los grafos de conocimiento y LLMs con RL logran predecir perturbaciones transcriptómicas con alta precisión, superando a métodos complejos. Descubre cómo.

Descubre cómo sGPO reduce a un tercio el costo de entrenamiento de RLVR intercambiando FLOPs de inferencia por eficiencia, sin perder rendimiento.

Descubre cómo el estudio PRIME revela que la IA aprende a explotar recompensas proxy antes de hackear, ofreciendo una señal temprana de desalineamiento.

RL4F: el benchmark de aprendizaje por refuerzo offline para control de plasma en fusión nuclear. Evaluamos métodos de RL e imitación en tareas de perfil completo con datos reales del tokamak DIII-D.

Descubre cómo RL con redes espectrales detecta y restaura apagones en redes eléctricas inteligentes en tiempo real. Aumenta la resiliencia.

Mejora la generación de ensamblajes LEGO con IA usando un método eficiente que evita errores de alineación y semántica. Descubre PVPO.

Descubre LEAF, un método RL que asigna ventajas por tramos en LLMs de voz. Supera a GRPO en QA y traducción, incluso con modelos más pequeños. ¡Lee más!

La simulación generativa optimiza evacuaciones de incendios forestales mientras captura carbono. Benchmarking con IA multiagente para infraestructuras.

Harness-1, un modelo de código abierto con solo 20B parámetros, supera a GPT-5.4 en búsqueda compleja. Descubre cómo su arquitectura externa logra mayor precisión.

Descubre cómo TRUST usa el aprendizaje por refuerzo alineado a la incertidumbre para mejorar las decisiones de llamada a herramientas en agentes LLM, reduciendo errores y aumentando la fiabilidad.
Descubre cómo PTD-PO optimiza políticas multimodales sin revelar respuestas, mejorando el razonamiento complejo.
StainFlow mejora el RL en agentes GUI con un modelo que rastrea manchas de entidades y vincula evidencia, aumentando un 3.2% el éxito en entornos dinámicos.

Descubre cómo la divulgación local revela covariables previas a la adaptación, permitiendo evaluar políticas sin interacciones repetidas.

RL para unir atención clínica y bienestar diario en salud mental. Estudio revela beneficios post-intervención y cómo evitar el burnout.